HTTP API
The HTTP API is the primary, low level API for syncing data with Electric.
HTTP API specification
API documentation is published as an OpenAPI specification:
- download the specification file to view or use with other OpenAPI tooling
- view the HTML documentation generated using Redocly
The rest of this page will describe the features of the API.
💡 If you haven't already, you may like to walkthrough the Quickstart to get a feel for using the HTTP API.
Syncing shapes
The API allows you to sync Shapes of data out of Postgres using the GET /v1/shape endpoint. The pattern is as follows.
First you make an initial sync request to get the current data for the Shape, such as:
curl -i 'http://localhost:3000/v1/shape?table=foo&offset=-1'Then you switch into a live mode to use long-polling to receive real-time updates. We'll go over these steps in more detail below. First a note on the data that the endpoint returns.
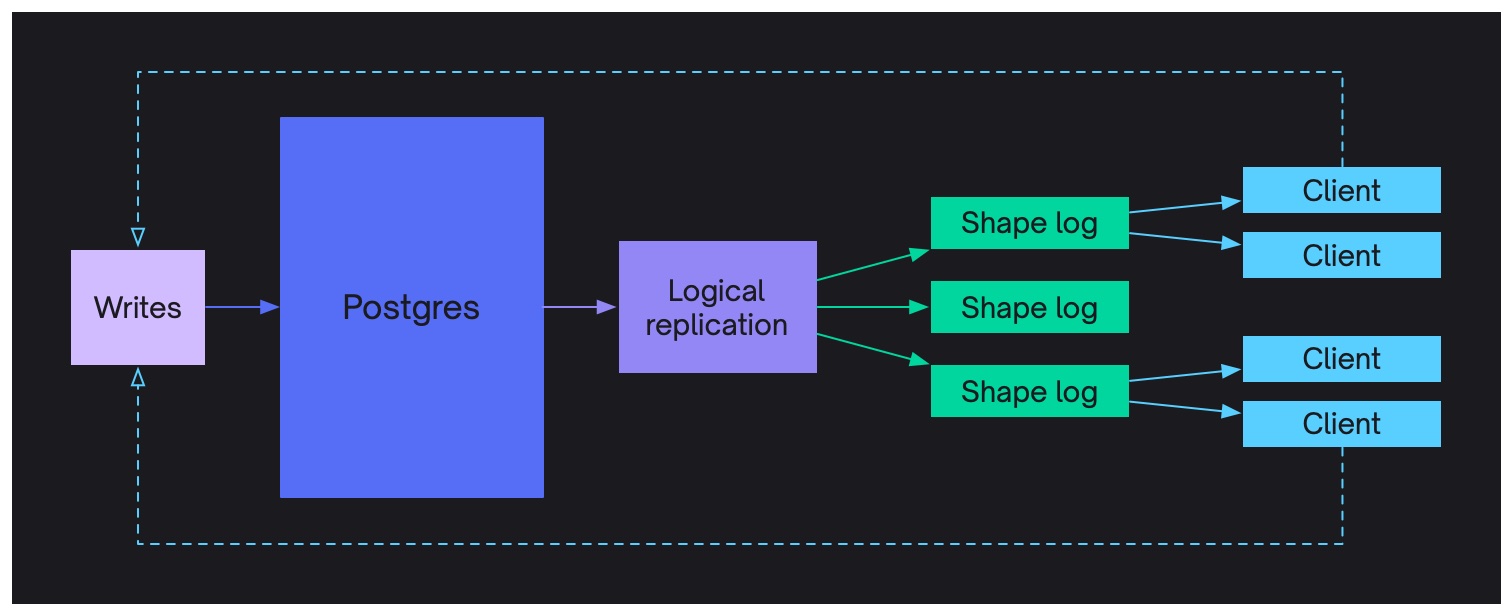
Shape Log
When you sync a shape from Electric, you get the data in the form of a log of logical database operations. This is the Shape Log.
The offset that you see in the messages and provide as the ?offset=... query parameter in your request identifies a position in the log. The messages you see in the response are shape log entries (the ones with values and action headers) and control messages (the ones with control headers).
The Shape Log is similar conceptually to the logical replication stream from Postgres. Except that instead of getting all the database operations, you're getting the ones that affect the data in your Shape. It's then the responsibility of the client to consume the log and materialize out the current value of the shape.
The values included in the shape log are strings formatted according to Postgres' display settings. The OpenAPI specification defines the display settings the HTTP API adheres to.
Initial sync request
When you make an initial sync request, with offset=-1, you're telling the server that you want the whole log, from the start for a given shape.
When a shape is first requested, Electric queries Postgres for the data and populates the log by turning the query results into insert operations. This allows you to sync shapes without having to pre-define them. Electric then streams out the log data in the response.
Sometimes a log can fit in a single response. Sometimes it's too big and requires multiple requests. In this case, the first request will return a batch of data and an electric-offset header. An HTTP client should then continue to make requests setting the offset parameter to the this header value. This allows the client to paginate through the shape log until it has received all the current data.
Control messages
The client will then receive an up-to-date control message at the end of the response data:
{"headers": {"control": "up-to-date"}}This indicates that the client has all the data that the server was aware of when fulfilling the request. The client can then switch into live mode to receive real-time updates.
Must-refetch
Note that the other control message is must-refetch which indicates that the client must throwaway their local shape data and re-sync from scratch:
{"headers": {"control": "must-refetch"}}Live mode
Once a client is up-to-date, it can switch to live mode to receive real-time updates, by making requests with live=true, an offset and a shape handle, e.g.:
curl -i 'http://localhost:3000/v1/shape?table=foo&live=true&handle=3833821-1721812114261&offset=0_0'The live parameter puts the server into live mode, where it will hold open the connection, waiting for new data arrive. This allows you to implement a long-polling strategy to consume real-time updates.
The server holds open the request until either a timeout (returning 204 No content) or when new data is available, which it sends back as the response. The client then reconnects and the server blocks again for new content. This way the client is always updated as soon as new data is available.
Clients
The algorithm for consuming the HTTP API described above can be implemented from scratch for your application. Howerver, it's typically implemented by clients that can be re-used and provide a simpler interface for application code.
There are a number of existing clients, such as the TypeScript and Elixir clients. If one doesn't exist for your language or environment, we hope that the pattern is simple enough that you should be able to write your own client quite simply.
Caching
HTTP API responses contain cache headers, including cache-control with max-age and stale-age and etag. These work out-of-the-box with caching proxies, such as Nginx, Caddy or Varnish, or a CDN like Cloudflare or Fastly.
There are three aspects to caching:
Accelerating initial sync
When a client makes a GET request to fetch shape data at a given offset, the response can be cached. Subsequent clients requesting the same data can be served from the proxy or CDN. This removes load from Electric (and from Postrgres) and allows data to be served extremely quickly, at the edge by an optimised CDN.
You can see an example Nginx config at packages/sync-service/dev/nginx.conf:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
# Enable gzip
gzip on;
gzip_types text/plain text/css application/javascript image/svg+xml application/json;
gzip_min_length 1000;
gzip_vary on;
# Enable caching
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=my_cache:10m max_size=1g inactive=60m use_temp_path=off;
server {
listen 3002;
location / {
proxy_pass http://host.docker.internal:3000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# Enable caching
proxy_cache my_cache;
proxy_cache_revalidate on;
proxy_cache_min_uses 1;
proxy_cache_methods GET HEAD;
proxy_cache_use_stale error timeout;
proxy_cache_background_update on;
proxy_cache_lock on;
# Add proxy cache status header
add_header X-Proxy-Cache $upstream_cache_status;
add_header X-Cache-Date $upstream_http_date;
}
}
}Caching in the browser
Requests are also designed to be cached by the browser. This allows apps to cache and avoid re-fetching data.
For example, say a page loads data by syncing a shape.

The next time the user navigates to the same page, the data is in the browser file cache.

This can make data access instant and available offline, even without using a persistent local store.
Coalescing live requests
Once a client has requested the initial data for a shape, it switches into live mode, using long polling to wait for new data. When new data arrives, the client reconnects to wait for more data, and so on.
Most caching proxies and CDNs support a feature called request coalescing. This identifies requests to the same resource, queues them on a waiting list, and only sends a single request to the origin.
Electric takes advantage of this to optimise realtime delivery to large numbers of concurrent clients. Instead of Electric holding open a connection per client, this is handled at the CDN level and allows us to coalesce concurrent long-polling requests in live mode.
This is how Electric can support millions of concurrent clients with minimal load on the sync service and no load on the source Postgres.